Python 爬图——基于xpath实现图片爬取
写在前面
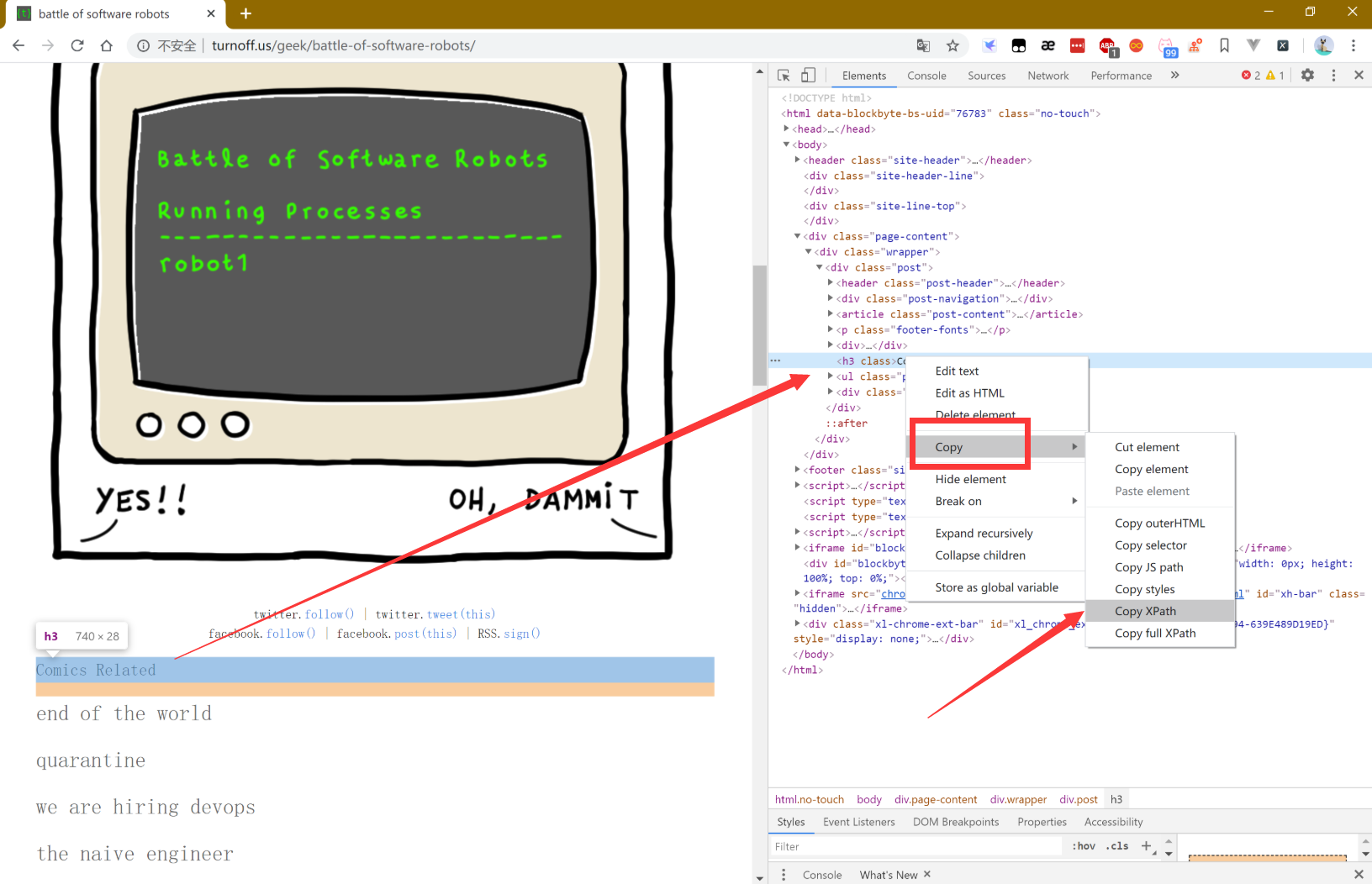
前段时间在网上冲浪的时候发现了一个有意思的网站:http://turnoff.us/,是一个极客漫画网站,他的创始人也是一个软件工程师,其漫画内容也别具一格,自嘲暗讽毒舌样样不少。这里贴出来几张:
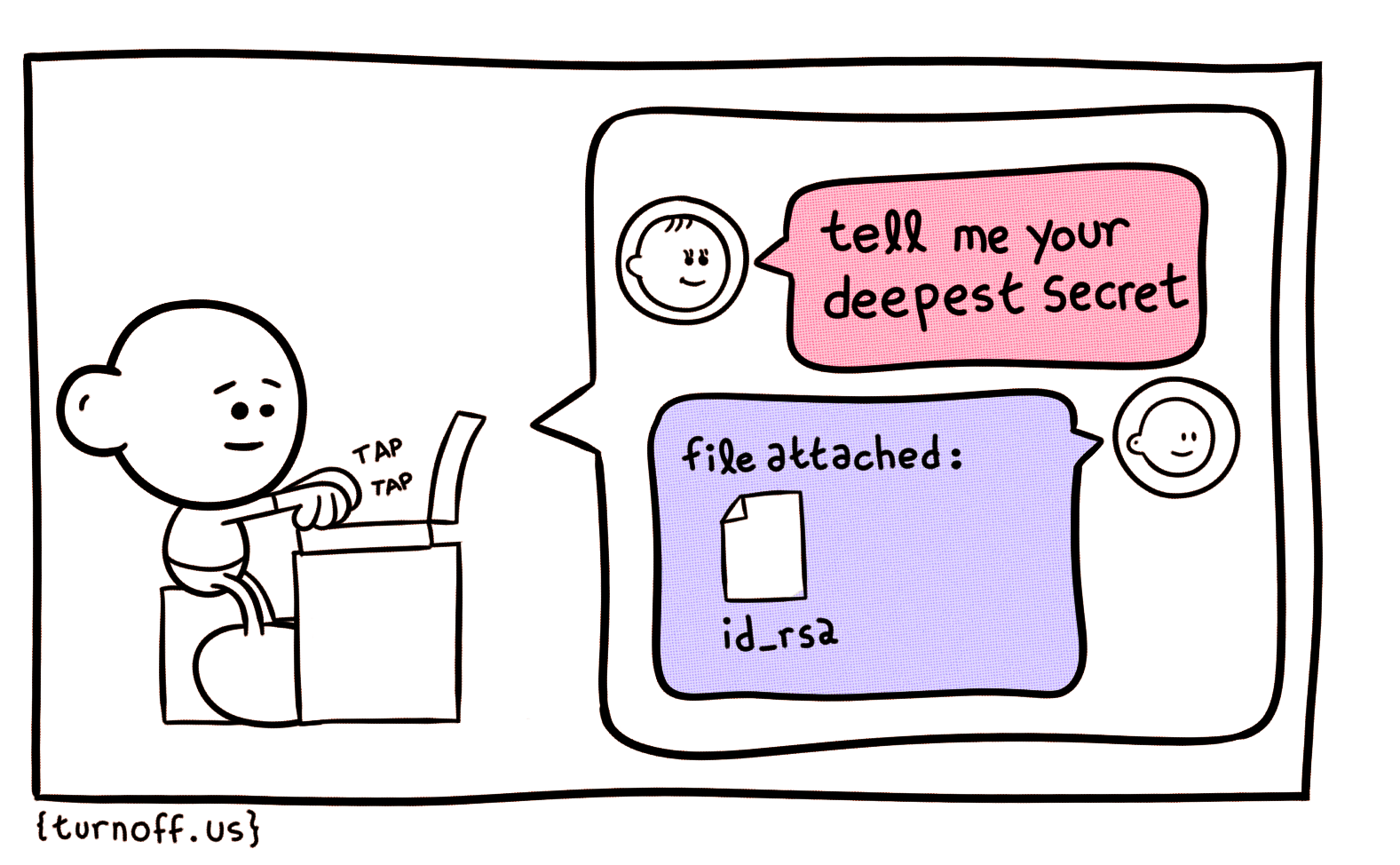


不过由于服务器可能在国外的原因,访问效果很是受限!既然如此那我们就让python来替我们去做吧
环境准备
由于我们使用python来编写小脚本,所以这里我们就不使用我们的重型武器pycharm了,我们选用轻便小巧的Subline Text来作为我们的工具
这里需要简单配置一下你的Subline text的编译环境来更加方便的运行 Python
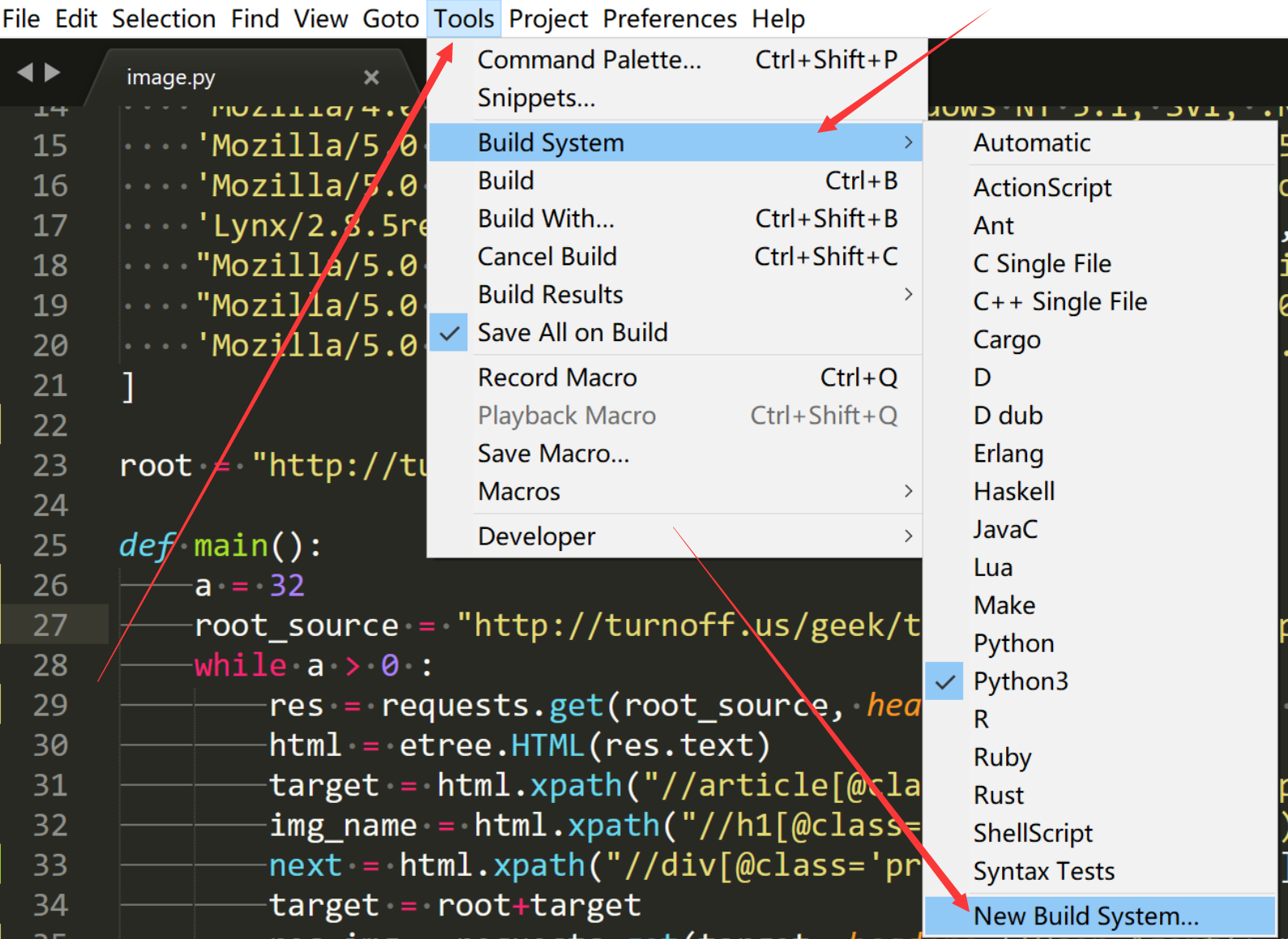
写入配置文件并保存到默认目录就行了
1
2
3
4
5
6
| {
"cmd": ["python","-u","$file"],
"selector": "source.pythona",
"encoding": "utf-8" ,
"env": {"PYTHONIOENCODING": "utf8"}
}
|
然后你的Build System的选项卡就有python3了
同时也可以快捷键Ctrl+B快速运行
依赖导入
这里我们需要一个基于xpath的第三方库—— lxml
关于 xpath
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。
XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 XPointer 都构建于 XPath 表达之上。
连接测试
这里我们依赖于一个request库来发起请求
1
2
3
4
5
6
| import request
res = requests.get("http://turnoff.us/")
print(res.text)
|
通过lxml来解析页面元素
1
2
3
4
5
6
7
8
| from lxml import etree
html = etree.HTML(res.text)
target = html.xpath("//article[@class='post-content']/p/img/@src")
print(target[0].encode('utf-8').decode())
|
关于xpath的表达式语法这里就不赘述,但这里给大家提供两种方法
谷歌插件 下载地址 (火狐也有对应插件)
Ctrl+Shift+x 调出窗口
Ctrl+shift+鼠标左键 选择元素
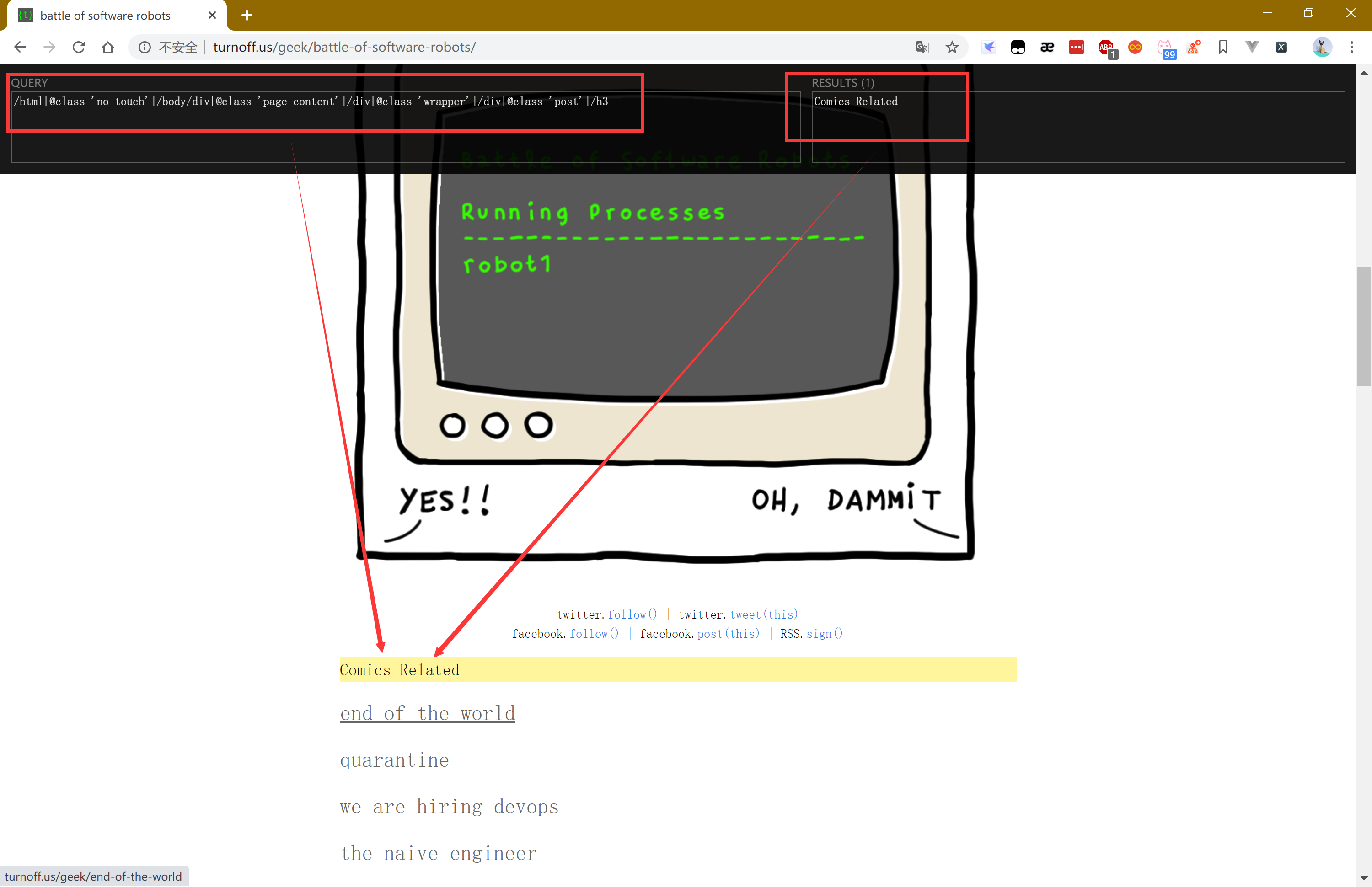
谷歌自带调试工具
开始爬图
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
| import requests
import os
import random
from lxml import etree
request_headers = [
"Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:30.0) Gecko/20100101 Firefox/30.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/537.75.14",
"Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Win64; x64; Trident/6.0)",
'Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11',
'Opera/9.25 (Windows NT 5.1; U; en)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)',
'Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)',
'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12',
'Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9',
"Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7",
"Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0",
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36'
]
root = "http://turnoff.us/"
def main():
a = 0
root_source = "http://turnoff.us/"
while a > 0 :
res = requests.get(root_source, headers={'User-Agent': random.choice(request_headers)})
html = etree.HTML(res.text)
target = html.xpath("//article[@class='post-content']/p/img/@src")[0].encode('utf-8').decode()[1:]
img_name = html.xpath("//h1[@class='post-title']/text()")[0].encode('utf-8').decode()[2:]
next = html.xpath("//div[@class='prev']/a[1]/@href")[0].encode('utf-8').decode()[1:]
target = root+target
res_img = requests.get(target, headers={'User-Agent': random.choice(request_headers)})
if not os.path.exists('./turnoff.us'):
os.mkdir('./turnoff.us')
img_path = 'turnoff.us/' + img_name + '.png'
fp = open(img_path,'wb')
fp.write(res_img.content)
fp.close
print("<= 第 "+ str(a) +" 张图片: "+img_name+" 下载完成 ---- 图片来源: "+target+"==>")
root_source = root + next
a += 1
if __name__ == '__main__':
main()
|
然后我们就可以去泡杯茶慢慢等就行了
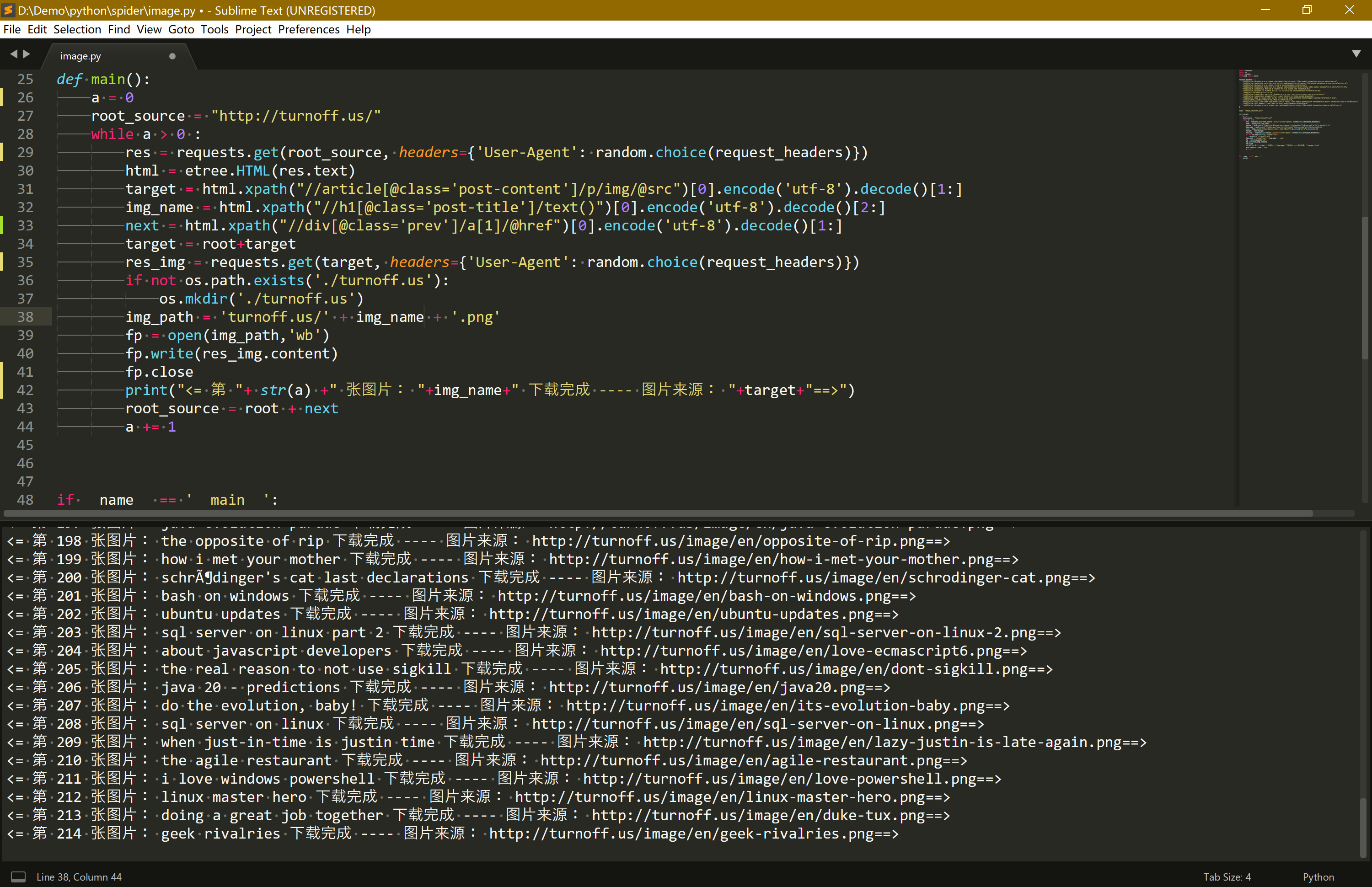
果然懒还是第一生产力
 wechat
wechat alipay
alipay




