GO 垃圾回收、异步调度和逃逸分析
GO 垃圾回收、异步调度和逃逸分析
一、垃圾回收
在理解垃圾回收之前,我们先理解一下Cache 和 Buffer,这两个都是缓存,这两者之间有什么区别呢?
- buffer:缓冲
用于存储速度不同步的设备或优先级不同的设备之间传输数据;通过buffer可以减少进程间通信需要等待的时间,当存储速度快的设备与存储速度慢的设备进行通信时,存储慢的数据先把数据存放到buffer,达到一定程度存储快的设备再读取buffer的数据,在此期间存储快的设备CPU可以做其他的事情。 - cache:缓存
是高速缓存,是位于CPU和主内存之间的容量较小但速度很快的存储器,因为CPU的速度远远高于主内存的速度,CPU从内存中读取数据需等待很长的时间,而 Cache保存着CPU刚用过的数据或循环使用的部分数据,这时从Cache中读取数据会更快,减少了CPU等待的时间,提高了系统的性能。
buffer是用于存放将要输出到disk(块设备)的数据,进行流量整形,把突发的大数量较小规模的 I/O 整理成平稳的小数量较大规模的 I/O,以减少响应次数,而cache是存放从disk上读出的数据,为了弥补高速设备和低速设备的鸿沟而引入的中间层,最终起到加快访问速度的作用。。二者都是为提高IO性能而设计的。
而Go标准库Buffer是一个可变大小的字节缓冲区,可以用Wirte和Read方法操作它.
Golang 垃圾回收发展史
通常在编程中的垃圾指内存中不再使用的内存区域,自动发现与释放这种内存区域的过程就是垃圾回收。
内存资源是有限的,而垃圾回收可以让内存重复使用,并且减轻开发者对内存管理的负担,减少程序中的内存问题。
我们透过这个来看下Go垃圾回收发展史:
go1.1,提高效率和垃圾回收精确度。
go1.3,提高了垃圾回收的精确度。
go1.4,之前版本的runtime大部分是使用C写的,这个版本大量使用Go进行了重写,让GC有了扫描stack的能力,进一步提高了垃圾回收的精确度。
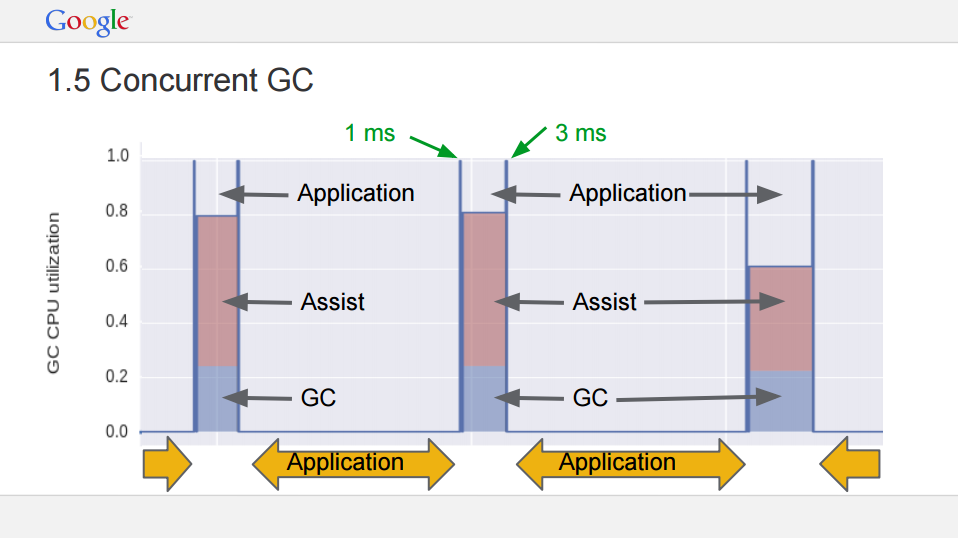
go1.5,目标是降低GC延迟,采用了并发标记和并发清除,三色标记,write barrier,以及实现了更好的回收器调度,设计文档1,文档2,以及这个版本的[Go talk]。
go1.6,小优化,当程序使用大量内存时,GC暂停时间有所降低。
go1.7,小优化,当程序有大量空闲goroutine,stack大小波动比较大时,GC暂停时间有显著降低。
go1.8,write barrier切换到hybrid write barrier,以消除STW中的re-scan,把STW的最差情况降低到50us,设计文档。
混合屏障的优势在于它允许堆栈扫描永久地使堆栈变黑(没有STW并且没有写入堆栈的障碍),这完全消除了堆栈重新扫描的需要,从而消除了对堆栈屏障的需求。重新扫描列表。特别是堆栈障碍在整个运行时引入了显着的复杂性,并且干扰了来自外部工具(如GDB和基于内核的分析器)的堆栈遍历。
此外,与Dijkstra风格的写屏障一样,混合屏障不需要读屏障,因此指针读取是常规的内存读取; 它确保了进步,因为物体单调地从白色到灰色再到黑色。
混合屏障的缺点很小。它可能会导致更多的浮动垃圾,因为它会在标记阶段的任何时刻保留从根(堆栈除外)可到达的所有内容。然而,在实践中,当前的Dijkstra障碍可能几乎保留不变。混合屏障还禁止某些优化:特别是,如果Go编译器可以静态地显示指针是nil,则Go编译器当前省略写屏障,但是在这种情况下混合屏障需要写屏障。这可能会略微增加二进制大小。
go1.9,提升指标主要是:
- 过去
runtime.GC,debug.SetGCPercent, 和debug.FreeOSMemory都不能触发并发GC,他们触发的GC都是阻塞的,go1.9可以了,变成了在垃圾回收之前只阻塞调用GC的goroutine。 debug.SetGCPercent只在有必要的情况下才会触发GC。
- 过去
go.1.10,小优化,加速了GC,程序应当运行更快一点点。
go1.12,显著提高了堆内存存在大碎片情况下的sweeping性能,能够降低GC后立即分配内存的延迟。
Go垃圾回收主要算法
Go语言提供的一个变量GOGC,用来对GC进行控制。该变量表示:最近一次GC过后,总的heap内存比所有可达节点所占用heap内存 大的百分比。如果GOGC=100则表示最近一次GC过后,总的heap内存比所有可达节点所占用heap内存大100%,即总heap内存是可达节点内存的2倍。
该值越大,则GC速度越快,但程序占用的内存较大,GC效果相对不明显。反之,则GC对内存的清理效果明显,但往往需要更多的时间。
GC 算法有四种:
- 引用计数(reference counting)
- 标记-清除(mark & sweep)
- 节点复制(Copying Garbage Collection)
- 分代收集(Generational Garbage Collection)。
引用计数(reference counting)
引用计数的思想:每个单元维护一个域,保存其它单元指向它的引用数量(类似有向图的入度)。当引用数量为0时,将其回收。引用计数是渐进式的,能够将内存管理的开销分布到整个程序之中。C++ 的 share_ptr 使用的就是引用计算方法。
引用计数算法实现一般是把所有的单元放在一个单元池里,比如类似 free list。这样所有的单元就被串起来了,就可以进行引用计数了。新分配的单元计数值被设置为 1(注意不是 0,因为申请一般都说 ptr = new object 这种)。每次有一个指针被设为指向该单元时,该单元的计数值加 1;而每次删除某个指向它的指针时,它的计数值减 1。
当其引用计数为 0 的时候,该单元会被进行回收。虽然这里说的比较简单,实现的时候还是有很多细节需要考虑,比如删除某个单元的时候,那么它指向的所有单元都需要对引用计数减 1。
- 优点
渐进式。内存管理与用户程序的执行交织在一起,将 GC 的代价分散到整个程序。不像标记-清扫算法需要 STW (Stop The World,GC 的时候挂起用户程序)。
算法易于实现。
内存单元能够很快被回收。相比于其他垃圾回收算法,堆被耗尽或者达到某个阈值才会进行垃圾回收。
- 缺点
原始的引用计数不能处理循环引用。大概这是被诟病最多的缺点了。不过针对这个问题,也除了很多解决方案,比如强引用等。
维护引用计数降低运行效率。内存单元的更新删除等都需要维护相关的内存单元的引用计数,相比于一些追踪式的垃圾回收算法并不需要这些代价。
单元池 free list 实现的话不是 cache-friendly 的,这样会导致频繁的 cache miss,降低程序运行效率。
标记-清除(mark & sweep)
标记-清除算法是第一种自动内存管理,基于追踪的垃圾收集算法。算法思想在 70 年代就提出了,是一种非常古老的算法。内存单元并不会在变成垃圾立刻回收,而是保持不可达状态,直到到达某个阈值或者固定时间长度。这个时候系统会挂起用户程序,也就是 STW,转而执行垃圾回收程序。
垃圾回收程序对所有的存活单元进行一次全局遍历确定哪些单元可以回收。算法分两个部分:标记(mark)和清除(sweep)。标记阶段表明所有的存活单元,清除阶段将垃圾单元回收。
标记-清除算法的优点也就是基于追踪的垃圾回收算法具有的优点:避免了引用计数算法的缺点(不能处理循环引用,需要维护指针)。缺点也很明显,需要 STW。
三色标记算法是对标记阶段的改进,原理如下:
- 起初所有对象都是白色。
- 从根出发扫描所有可达对象,标记为灰色,放入待处理队列。
- 从队列取出灰色对象,将其引用对象标记为灰色放入队列,自身标记为黑色。
- 重复 3,直到灰色对象队列为空。此时白色对象即为垃圾,进行回收。
三色法标记主要是第一部分是扫描所有对象进行三色标记,标记为黑色、灰色和白色,标记完成后只有黑色和白色对象,黑色代表使用中对象,白色对象代表垃圾,灰色是白色过渡到黑色的中间临时状态,第二部分是清扫垃圾,即清理白色对象。
第一部分包含了栈扫描、标记和标记结束3个阶段。在栈扫描之前有2个重要的准备:STW(Stop The World)和开启写屏障(WB,Write Barrier)。
STW是Stop The World,指会暂停所有正在执行的用户线程/协程,进行垃圾回收的操作,在这之前会进行一些准备工作,比如开启Write Barrier,把全局变量,以及每个goroutine中的 Root对象 收集起来,Root对象是标记扫描的源头,可以从Root对象依次索引到使用中的对象,STW为垃圾对象的扫描和标记提供了必要的条件。
每个P都有一个 mcache ,每个 mcache 都有1个Span用来存放 TinyObject,TinyObject 都是不包含指针的对象,所以这些对象可以直接标记为黑色,然后关闭 STW。
每个P都有1个进行扫描标记的 goroutine,可以进行并发标记,关闭STW后,这些 goroutine 就变成可运行状态,接收 Go Scheduler 的调度,被调度时执行1轮标记,它负责第1部分任务:栈扫描、标记和标记结束。
栈扫描阶段就是把前面搜集的Root对象找出来,标记为黑色,然后把它们引用的对象也找出来,标记为灰色,并且加入到gcWork队列,gcWork队列保存了灰色的对象,每个灰色的对象都是一个Work。
后面可以进入标记阶段,它是一个循环,不断的从gcWork队列中取出work,所指向的对象标记为黑色,该对象指向的对象标记为灰色,然后加入队列,直到队列为空。
然后进入标记结束阶段,再次开启STW,不同的版本处理方式是不同的。
在Go1.7的版本是Dijkstra写屏障,这个写屏障只监控堆上指针数据的变动,由于成本原因,没有监控栈上指针的变动,由于应用goroutine和GC的标记goroutine都在运行,当栈上的指针指向的对象变更为白色对象时,这个白色对象应当标记为黑色,需要再次扫描全局变量和栈,以免释放这类不该释放的对象。
在Go1.8及以后的版本引入了混合写屏障,这个写屏障依然不监控栈上指针的变动,但是它的策略,使得无需再次扫描栈和全局变量,但依然需要STW然后进行一些检查。
标记结束阶段的最后会关闭写屏障,然后关闭STW,唤醒熟睡已久的负责清扫垃圾的goroutine。
清扫goroutine是应用启动后立即创建的一个后台goroutine,它会立刻进入睡眠,等待被唤醒,然后执行垃圾清理:把白色对象挨个清理掉,清扫goroutine和应用goroutine是并发进行的。清扫完成之后,它再次进入睡眠状态,等待下次被唤醒。
最后执行一些数据统计和状态修改的工作,并且设置好触发下一轮GC的阈值,把GC状态设置为Off。
这写基本是Go垃圾回收的流程,但是在go1.12的源码稍微有一些不同,例如在标记结束后,就开始设置各种状态数据以及把GC状态成了Off,在开启一轮GC时,会自动检测当前是否处于Off,如果不是Off,则当前goroutine会调用清扫函数,帮助清扫goroutine一起清扫span,实际的Go垃圾回收流程以源码为准。
这里需要提下go的对象大小定义:
- 大对象是大于32KB的.
- 小对象16KB到32KB的.
- Tiny对象指大小在1Byte到16Byte之间并且不包含指针的对象.
三色标记的一个明显好处是能够让用户程序和 mark 并发的进行.
节点复制(Copying Garbage Collection)
节点复制也是基于追踪的算法。其将整个堆等分为两个半区(semi-space),一个包含现有数据,另一个包含已被废弃的数据。节点复制式垃圾收集从切换(flip)两个半区的角色开始,然后收集器在老的半区,也就是 Fromspace 中遍历存活的数据结构,在第一次访问某个单元时把它复制到新半区,也就是 Tospace 中去。
在 Fromspace 中所有存活单元都被访问过之后,收集器在 Tospace 中建立一个存活数据结构的副本,用户程序可以重新开始运行了。
- 优点
- 所有存活的数据结构都缩并地排列在 Tospace 的底部,这样就不会存在内存碎片的问题
- 获取新内存可以简单地通过递增自由空间指针来实现。
- 缺点
- 内存得不到充分利用,总有一半的内存空间处于浪费状态。
分代收集(Generational Garbage Collection)
基于追踪的垃圾回收算法(标记-清扫、节点复制)一个主要问题是在生命周期较长的对象上浪费时间(长生命周期的对象是不需要频繁扫描的)。同时,内存分配存在这么一个事实 “most object die young”。基于这两点,分代垃圾回收算法将对象按生命周期长短存放到堆上的两个(或者更多)区域,这些区域就是分代(generation)。对于新生代的区域的垃圾回收频率要明显高于老年代区域。
分配对象的时候从新生代里面分配,如果后面发现对象的生命周期较长,则将其移到老年代,这个过程叫做 promote。随着不断 promote,最后新生代的大小在整个堆的占用比例不会特别大。收集的时候集中主要精力在新生代就会相对来说效率更高,STW 时间也会更短。
- 优点
- 性能更优。
- 缺点
- 实现复杂。
Golang GC
Golang GC 有两种,非增量式垃圾回收和增量式垃圾回收.
非增量式垃圾回收需要STW,在STW期间完成所有垃圾对象的标记,STW结束后慢慢的执行垃圾对象的清理。
增量式垃圾回收也需要STW,在STW期间完成部分垃圾对象的标记,然后结束STW继续执行用户线程,一段时间后再次执行STW再标记部分垃圾对象,这个过程会多次重复执行,直到所有垃圾对象标记完成。
GC算法有3大性能指标:吞吐量、最大暂停时间(最大的STW占时)、内存占用率。增量式垃圾回收不能提高吞吐量,但和非增量式垃圾回收相比,每次STW的时间更短,能够降低最大暂停时间,就是Go每个版本Release Note中提到的GC延迟、GC暂停时间。
然而Golang GC STW的时候减少最大暂停时间还有一种思路:并发垃圾回收,注意不是并行垃圾回收。
并行垃圾回收是每个核上都跑垃圾回收的线程,同时进行垃圾回收,这期间为STW,会暂停用户线程的执行。
并发垃圾回收是先STW找到所有的Root对象,然后结束STW,让垃圾标记线程和用户线程并发执行,垃圾标记完成后,再次开启STW,再次扫描和标记,以免释放使用中的内存。
并发垃圾回收和并行垃圾回收的重要区别就是不会持续暂停用户线程,并发垃圾回收也降低了STW的时间,达到了减少最大暂停时间的目的。
在堆上分配大于 32K byte 对象的时候进行检测此时是否满足垃圾回收条件,如果满足则进行垃圾回收。
1 | func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer { |
上面是自动垃圾回收,还有一种是主动垃圾回收,通过调用 runtime.GC(),这是阻塞式的。
1 | // GC runs a garbage collection and blocks the caller until the |
GC 触发条件
GC有3种触发方式:
辅助GC
在分配内存时,会判断当前的Heap内存分配量是否达到了触发一轮GC的阈值(每轮GC完成后,该阈值会被动态设置),如果超过阈值,则启动一轮GC。调用runtime.GC()强制启动一轮GC。
sysmon是运行时的守护进程,当超过 forcegcperiod (2分钟)没有运行GC会启动一轮GC。
forceTrigger 是 forceGC 的标志,后面意思是当前堆上的活跃对象大于我们初始化时候设置的 GC 触发阈值。在 malloc 以及 free 的时候 heap_live 会一直进行更新,这里就不再展开了。
1 | // gcShouldStart returns true if the exit condition for the _GCoff |
- forcegc
自动检测和用户主动调用, 除此之外 Golang 本身还会对运行状态进行监控,如果超过两分钟没有 GC,则触发 GC。监控函数是 sysmon(),在主 goroutine 中启动。
1 | // The main goroutine |
垃圾回收的主要流程
为什么需要三色标记?
三色标记的目的,主要是利用Tracing GC(Tracing GC 是垃圾回收的一个大类,另外一个大类是引用计数)做增量式垃圾回收,降低最大暂停时间。原生Tracing GC只有黑色和白色,没有中间的状态,这就要求GC扫描过程必须一次性完成,得到最后的黑色和白色对象。在前面增量式GC中介绍到了,这种方式会存在较大的暂停时间。
三色标记增加了中间状态灰色,增量式GC运行过程中,应用线程的运行可能改变了对象引用树,只要让黑色对象直接引用白色对象,GC就可以增量式的运行,减少停顿时间。
什么是三色标记?
三色标记,通过字面意思我们就可以知道它由3种颜色组成:
黑色 Black:表示对象是可达的,即使用中的对象,黑色是已经被扫描的对象。
灰色 Gary:表示被黑色对象直接引用的对象,但还没对它进行扫描。
白色 White:白色是对象的初始颜色,如果扫描完成后,对象依然还是白色的,说明此对象是垃圾对象。
三色标记规则:黑色不能指向白色对象。即黑色可以指向灰色,灰色可以指向白色。
三色标记法,主要流程如下:
初始所有对象被标记为白色。
从 root 开始找到所有可达对象,标记为灰色,放入待处理队列。
遍历灰色对象队列,将其引用对象标记为灰色放入待处理队列,自身标记为黑色。
处理完灰色对象队列,直到没有灰色对象。
剩余白色对象为垃圾对象,执行清扫工作。
详细的过程如下图所示:

这里需要解释下:
首先从 root 开始遍历,root 包括全局指针和 goroutine 栈上的指针。
mark 有两个过程。第一是从 root 开始遍历,标记为灰色。遍历灰色队列。第二re-scan 全局指针和栈。因为 mark 和用户程序是并行的,所以在过程 1 的时候可能会有新的对象分配,这个时候就需要通过写屏障(write barrier)记录下来。re-scan 再完成检查一下。
Stop The World 有两个过程。第一个是 GC 将要开始的时候,这个时候主要是一些准备工作,比如 enable write barrier。第二个过程就是上面提到的 re-scan 过程。如果这个时候没有 stw,那么 mark 将无休止。
另外针对上图各个阶段对应 GCPhase 如下:
- Off: _GCoff
- Stack scan - Mark: _GCmark
- Mark termination: _GCmarktermination
写屏障 (write barrier)
垃圾回收中的 write barrier 可以理解为编译器在写操作时特意插入的一段代码,对应的还有 read barrier。
为什么需要 write barrier,很简单,对于和用户程序并发运行的垃圾回收算法,用户程序会一直修改内存,所以需要记录下来。
Golang 1.7 之前的 write barrier 使用的经典的 Dijkstra-style insertion write barrier [Dijkstra ‘78], STW 的主要耗时就在 stack re-scan 的过程。自 1.8 之后采用一种混合的 write barrier 方式 (Yuasa-style deletion write barrier [Yuasa ‘90] 和 Dijkstra-style insertion write barrier [Dijkstra ‘78])来避免 re-scan。
标记
垃圾回收的代码主要集中在函数 gcStart() 中。
1 | // gcStart 是 GC 的入口函数,根据 gcMode 做处理。 |
STW phase 1
在 GC 开始之前的准备工作。
1 | func gcStart(mode gcMode, forceTrigger bool) { |
Mark
Mark 阶段是并行的运行,通过在后台一直运行 mark worker 来实现。
1 | func gcStart(mode gcMode, forceTrigger bool) { |
Mark 阶段的标记代码主要在函数 gcDrain() 中实现。
1 | // gcDrain scans roots and objects in work buffers, blackening grey |
Mark termination (STW phase 2)
mark termination 阶段会 stop the world。函数实现在 gcMarkTermination()。
1 | func gcMarkTermination() { |
清扫
1 | func gcSweep(mode gcMode) { |
并行式清扫,在 GC 初始化的时候就会启动 bgsweep(),然后在后台一直循环
1 | func bgsweep(c chan int) { |
不管是阻塞式还是并行式,都是通过 sweepone()函数来做清扫工作的.内存管理都是基于 span 的,mheap_ 是一个全局的变量,所有分配的对象都会记录在 mheap_ 中。在标记的时候,我们只要找到对对象对应的 span 进行标记,清扫的时候扫描 span,没有标记的 span 就可以回收了。
1 | // sweeps one span |
GC调节参数
Go垃圾回收为了保证使用的简洁性,只提供了一个参数GOGC。GOGC代表了占用中的内存增长比率,达到该比率时应当触发1次GC,该参数可以通过环境变量设置。
GOGC参数取值范围为0~100,默认值是100,单位是百分比。
假如当前heap占用内存为4MB,GOGC = 75,
1 | 4 * (1+75%) = 7MB |
等heap占用内存大小达到7MB时会触发1轮GC。
GOGC还有2个特殊值:
“off” : 代表关闭GC
0 : 代表持续进行垃圾回收,只用于调试
二、异步抢占式调度
go 1.14 版本带来了一个非常重要的特性:异步抢占的调度模式。之前通过解释协程调度原理中提到,协程是用户态实现的自我调度单元,每个协程都是君子才能维护和谐的调度秩序,如果出现了流氓(占着 cpu 不放的协程)那就是是无可奈何的。
go1.14 之前的版本所谓的抢占调度是怎么样的呢下面我们一起看下?
- 如果
sysmon监控线程发现有个协程 A 执行之间太长了(或者 gc 场景,或者 stw 场景),那么会友好的在这个 A 协程的某个字段设置一个抢占标记. - 协程 A 在 call 一个函数的时候,会复用到扩容栈(morestack)的部分逻辑,检查到抢占标记之后,让出 cpu,切到调度主协程里.
这样 A 就算是被抢占了。我们注意到,A 调度权被抢占有个前提:A 必须主动 call 函数,这样才能有走到 morestack 的机会(能抢占君子的调度,无法抢占流氓的调度权).
这里我们用一个 P(处理器),用来确保是单处理器的场景.
通过golang 的 GMP 模型:调度单元 G,线程 M,队列 P,由于 P 只有一个,所以每时每刻有效执行的 M 只会有一个,也就是单处理器的场景(旁白:个人理解有所不同,有些人喜欢直接把 P 理解成处理器,我这里把 P 说成队列是从实现的角度来讲的).
通过打开 golang 调试器 trace 工具(可以直观的观察调度的情况),搞一个纯计算且耗时的函数 calculateSum.
下面创建一个名为 main.go 的文件,写入以下内容:
1 | package main |
我们分别看下 go1.13, go.14 对于这个程序的表现区别。
trace 这个就再简单提下,trace 是 golang 内置的一种调试手段,能够 trace 一段时间程序的运行情况。能看到:
- 协程的调度运行情况;
- 跑在每个处理器 P 上协程情况;
- 协程出发的事件链;
- 编译、运行的程序:
1 | > go build -gcflags "-N -l" ./main.go |
这样在本地就能生成一个 trace.output 文件;
分析 trace 输出:
1 | > go tool trace -http=":8080" ./trace.output |
这样就可以直接用浏览器来方便查看分析的结果,如下:

详细解析:
1 | * View trace:查看跟踪(这个是今天要使用的重点),能看到一段时间内 goroutine 的调度执行情况,包括事件触发链; |
所以我们要是分析抢占只需要分析View trace。
- 横坐标为时间线,表示采样的顺序时间;
- 纵坐标为采样的指标,分为两大块:STATS,PROCS
注意: 这些采样值都要配合时间轴来看,理解成是一些快照数据.
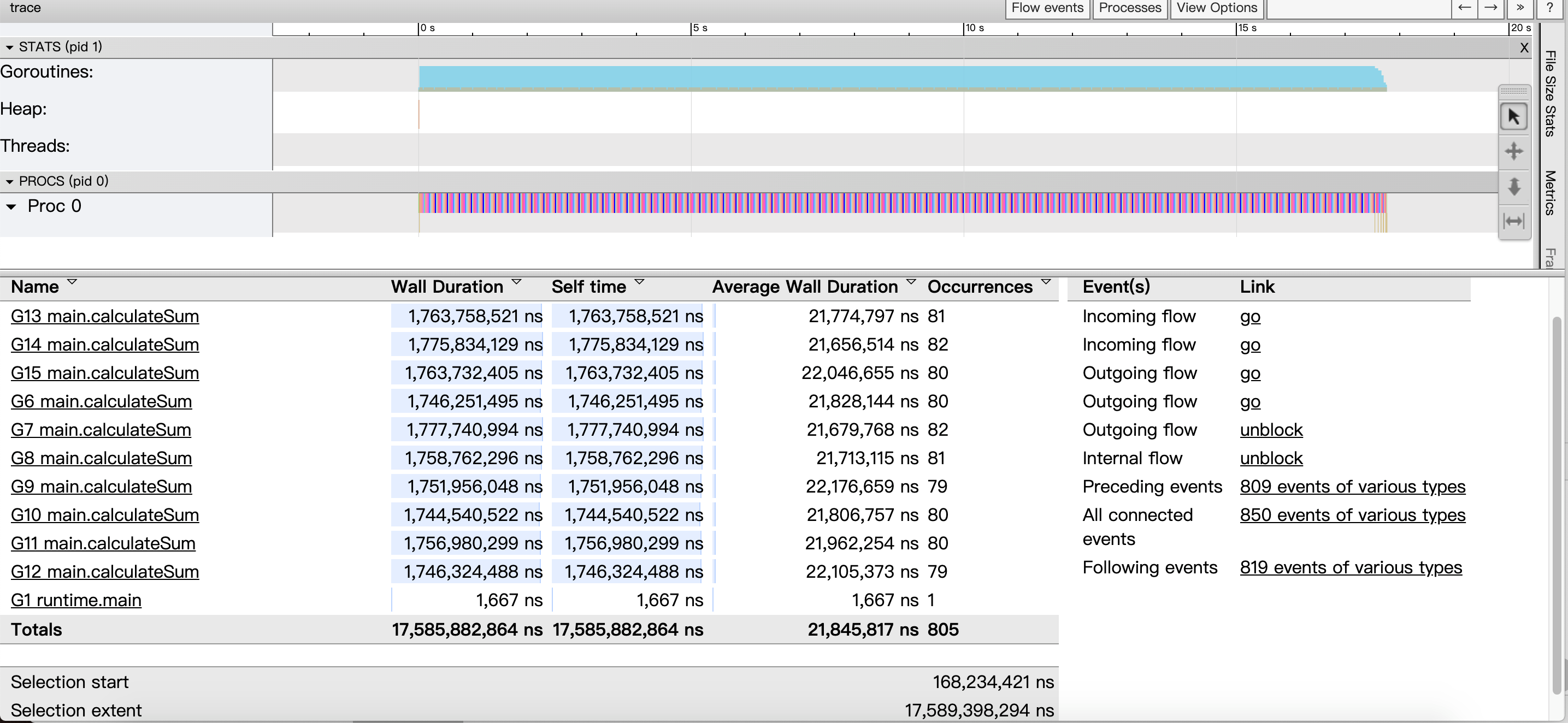
STATS:
处于上半区,展示的有三个指标: Goroutines,Heap,Threads,鼠标点击彩色的图样,就能看到这一小段时间的采样情况.
- Goroutines:展示某个时间 GCWaiting,Runnable,Running 三种状态的协程个数;
- Heap:展示某个时间的 NextGC,Allocated 的值;
- Threads:展示 InSyscall,Running 两个状态的线程数量情况;
PROCS:
显示每个处理器当时正在处理的协程,事件,和一些具体运行时信息, Proc 的个数由 GOMAXPROCS 参数控制,默认和机器核心数一致.
点击一个协程区域,就会显示这个时间段的情况,有一些指标:
1 | * Start:开始时间(就是时间轴上的刻度). |
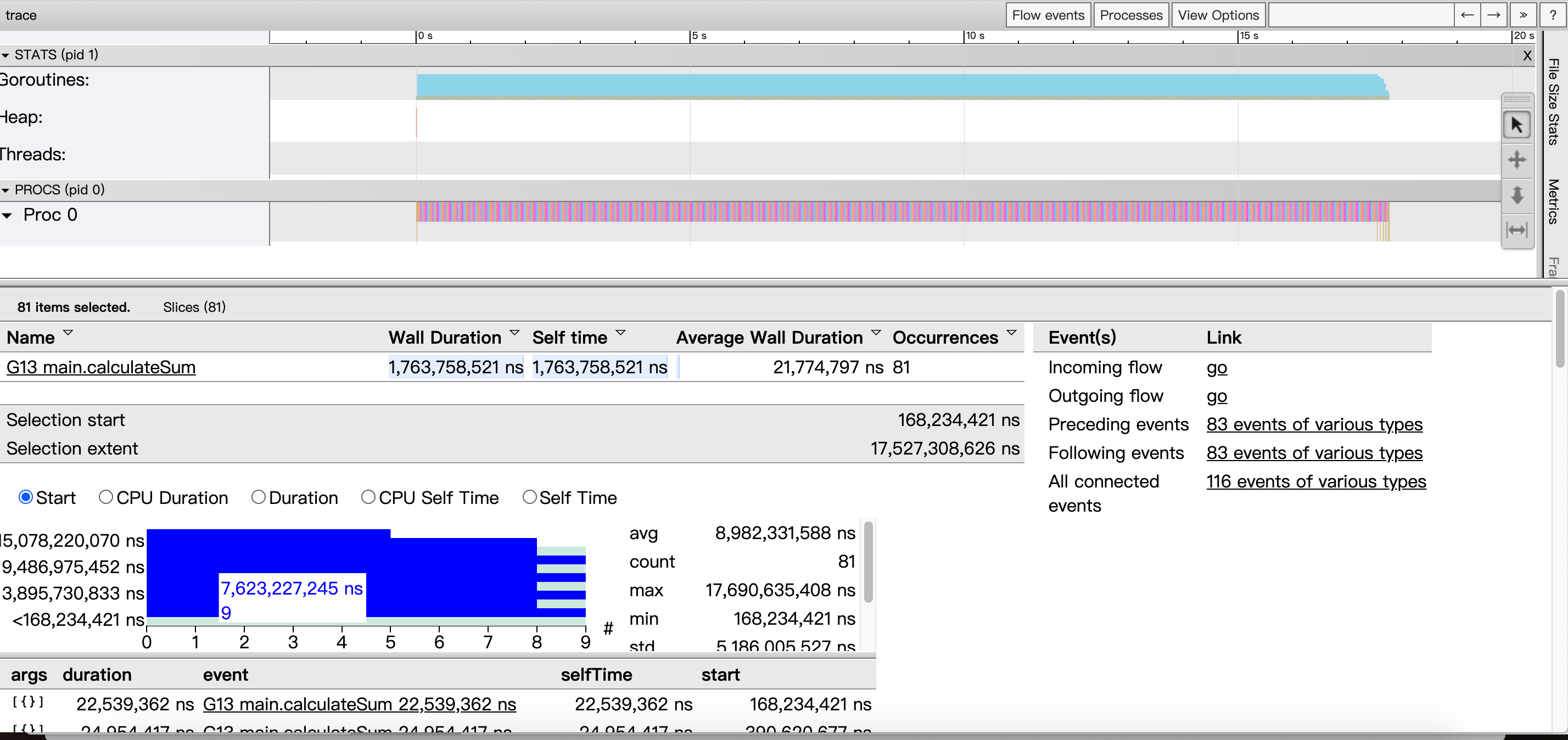
从trace图中我们可以看出:
只有一个处理器(Proc 0)调度协程;因为我们代码里面设置 GOMAXPROCS = 1, 程序运行的总时间还是 16s(虽然 10 个 goroutine 是并发运行的,但是你只有一个处理器,所以时间肯定是一样的,但如果你有多个处理器的时候,就不一样了);这个 goroutine 只执行了 20ms 就让出处理器了;
我们大概知道,main.go 里面 calculateSum函数在我的机器上大概需要 1.6s 的时间,所以执行 20ms 就切走了肯定是还没有执行完的,是被强制抢占了处理器;
因此可以从go1.14 看出抢占式任务调度,让 goroutine 任务的调度执行更加公平,避免了流氓协程降低整个系统吞吐能力的情况发生;通过 trace 工具图形化展示了go1.14 的调度执行情况,从 trace 结果来看,非常直观.
我们理解了抢占调度带来的好处,并且形象的观测到了,并且还发现了 runtime.asyncPreempt 这个函数(是通过异步信号来实现的);
三、逃逸分析
通常在编译代码的时候,编译器根据分析,判断将变量分配在栈或堆上。函数定义中,一般将局部变量和参数分配到栈上(stack frame)上。但是,如果编译器不能确定在函数返回(return)时,变量是否被引用(reference),分配到堆上;如果局部变量非常大,也应分配在堆上。
如果对变量取地址(*和&操作),则有可能分配在堆上。此外,还需要进行逃逸分析(escape analytic),判断return后变量是否被引用,不引用分配到栈上,引用分配到堆上。
在golang中逃逸分析是一种确定指针动态范围的方法,可以分析在程序的哪些地方可以访问到指针。它涉及到指针分析和形状分析。当一个变量(或对象)在子程序中被分配时,一个指向变量的指针可能逃逸到其它执行线程中,或者去调用子程序。如果使用尾递归优化(通常在函数编程语言中是需要的),对象也可能逃逸到被调用的子程序中。 如果一个子程序分配一个对象并返回一个该对象的指针,该对象可能在程序中的任何一个地方被访问到——这样指针就成功“逃逸”了。如果指针存储在全局变量或者其它数据结构中,它们也可能发生逃逸,这种情况是当前程序中的指针逃逸。 逃逸分析需要确定指针所有可以存储的地方,保证指针的生命周期只在当前进程或线程中。
但是golang 编译器决定变量应该分配到什么地方时会进行逃逸分析,下面我们看段代码:
1 | package main |
运行后:
1 | > go run -gcflags '-m -l' escape.go |
foo() 中的 x 最后在堆上分配,而 bar() 中的 x 最后分配在了栈上。在官网 (golang.org) FAQ 上有一个关于变量分配的问题如下:
From a correctness standpoint, you don’t need to know. Each variable in Go exists as long as there are references to it.
The storage location chosen by the implementation is irrelevant to the semantics of the language.The storage location does have an effect on writing efficient programs. When possible, the Go compilers will allocate variables that are local to a function in that function’s stack frame.
However, if the compiler cannot prove that the variable is not referenced after the function returns,
then the compiler must allocate the variable on the garbage-collected heap to avoid dangling pointer errors.
Also, if a local variable is very large, it might make more sense to store it on the heap rather than the stack.In the current compilers, if a variable has its address taken, that variable is a candidate for allocation on the heap.
However, a basic escape analysis recognizes some cases when such variables will not live past the return from the function and can reside on the stack.
翻译过来就是:
如何得知变量是分配在栈(stack)上还是堆(heap)上?
准确地说,你并不需要知道。Golang 中的变量只要被引用就一直会存活,存储在堆上还是栈上由内部实现决定而和具体的语法没有关系。
知道变量的存储位置确实和效率编程有关系。如果可能,Golang 编译器会将函数的局部变量分配到函数栈帧(stack frame)上。
然而,如果编译器不能确保变量在函数 return之后不再被引用,编译器就会将变量分配到堆上。而且,如果一个局部变量非常大,那么它也应该被分配到堆上而不是栈上。
当前情况下,如果一个变量被取地址,那么它就有可能被分配到堆上。然而,还要对这些变量做逃逸分析,如果函数return之后,变量不再被引用,则将其分配到栈上。
其实在golang中所有静态内存的其实分配都是在 stack 上进行的,而函数体在执行结束出栈后所有在栈上分配的内存都将得到释放,如果此时直接返回当前作用域变量的指针,这在下层函数的寻址行为就会因为出栈的内存释放而造成空指针异常。这个时候我们就得需要用到malloc在堆上(heap)动态分配内存,自己管理内存的生命周期,自己手动释放才是安全的方式。
然而escape analysis的存在让go完美规避了这些问题,编译器在编译时对代码做了分析,如果发现当前作用域的变量没有超出函数范围,则会自动在stack上分配,如果找不到了,则会在heap上分配。这样其实开发者就不用太关心堆栈的使用边界,在代码层面上完全不需要关心内存的分配,把底层要考虑的问题交给编译器,同时也减小了gc回收的压力。
go在一定程度消除了堆和栈的区别,因为go在编译的时候进行逃逸分析,来决定一个对象放栈上还是放堆上,不逃逸的对象放栈上,可能逃逸的放堆上。
那么逃逸分析的作用是什么呢?
1.逃逸分析的好处是为了减少gc的压力,不逃逸的对象分配在栈上,当函数返回时就回收了资源,不需要gc标记清除。
2.逃逸分析完后可以确定哪些变量可以分配在栈上,栈的分配比堆快,性能好(逃逸的局部变量会在堆上分配 ,而没有发生逃逸的则有编译器在栈上分配)。
3.同步消除,如果你定义的对象的方法上有同步锁,但在运行时,却只有一个线程在访问,此时逃逸分析后的机器码,会去掉同步锁运行。
我们在开发的时候其实也可以自己去设置和查看逃逸分析的log,我们可以分析逃逸日志,只要在编译的时候加上-gcflags ‘-m’,但是我们为了不让编译时自动内连函数,一般会加-l参数,最终为-gcflags ‘-m -l’.在main中可以用:
1 | go run -gcflags '-m -l' main.go |
那么接着就会有个问题什么时候会逃逸,什么时候不会逃逸呢?
接下来我们看个例子:
1 | package main |
运行后:
1 | main.go:11: leaking param: m to result ~r1 level=0 |
在这里的m变量是“流式”,因为identity这个函数仅仅输入一个变量,又将这个变量作为返回输出,但identity并没有引用m,所以这个变量没有逃逸,而e没有被引用,且生命周期也在mian里,e没有逃逸,分配在栈上。
通常在go中函数都是运行在栈上的,在栈声明临时变量分配内存,函数运行完毕在回收该段栈空间,并且每个函数的栈空间都是独立的,不能被访问到的。但是在某些情况下,栈上的空间需要在该函数被释放后依旧能访问到,这时候就涉及到内存的逃逸了
1 | type data struct { |
这里的patent1和patent2函数都有返回值,唯一不同的地方是patent1返回data结构体,patent2返回data结构体指针。在大多数语言例如C类似patent2的函数是不对的,因为p是一个临时变量,返回过后就会被释放掉,返回毫无意义。但是在golang中,这种语法是允许的,它能正确的把p的地址返回到上层调用函数而不被释放。
这样该函数在运行完毕后肯定是要释放的,内部分配的临时内存也要释放,所以p也应该被释放。而为了让p能被正确返回到上层调用,golang采取了一种内存策略,把p从栈拿到堆的中去,此时p就不会跟随patent2一同消亡了,这个过程就是逃逸。
 wechat
wechat alipay
alipay







